In the previous article of this 2-part blog, I outlined how Row-Level security can be implemented using Amazon Spectrum and Redshift. This involved using a materialized view to persist the spectrum data involving materialized views as summarised below:
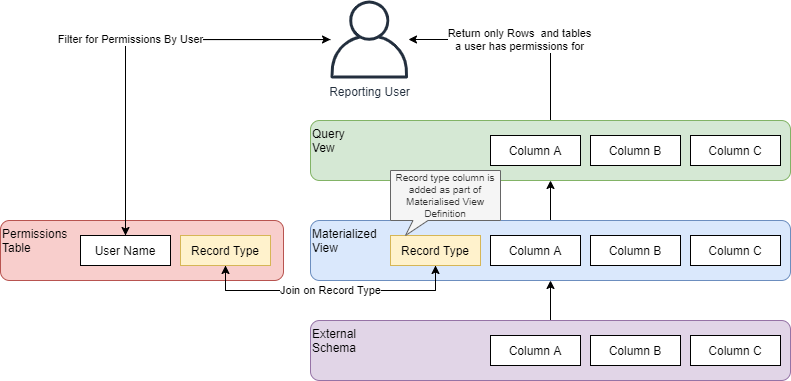
Please refer to that article for more detailed information on that approach.
However, creating the materialized views and accompanying Query Views is not something that you wish to manage manually – glue Database Tables will change frequently, meaning such an approach would have a heavy operational management cost. Instead, we want to automate the creation of these views.
Luckily, using AWS, this is straightforward to do and involves:
- Creating Glue Event triggers based on the “Glue Data Catalog Database State Change” and “Glue Data Catalog Table State Change” events. The “Glue Data Catalog Database State Change” event is triggered when a Table is created or deleted. The “Glue Data Catalog Table State Change” event is triggered when a table is updated;
- Creating a Lambda (I used Java) that will connect to Redshift and, depending on the event type, update the database accordingly.
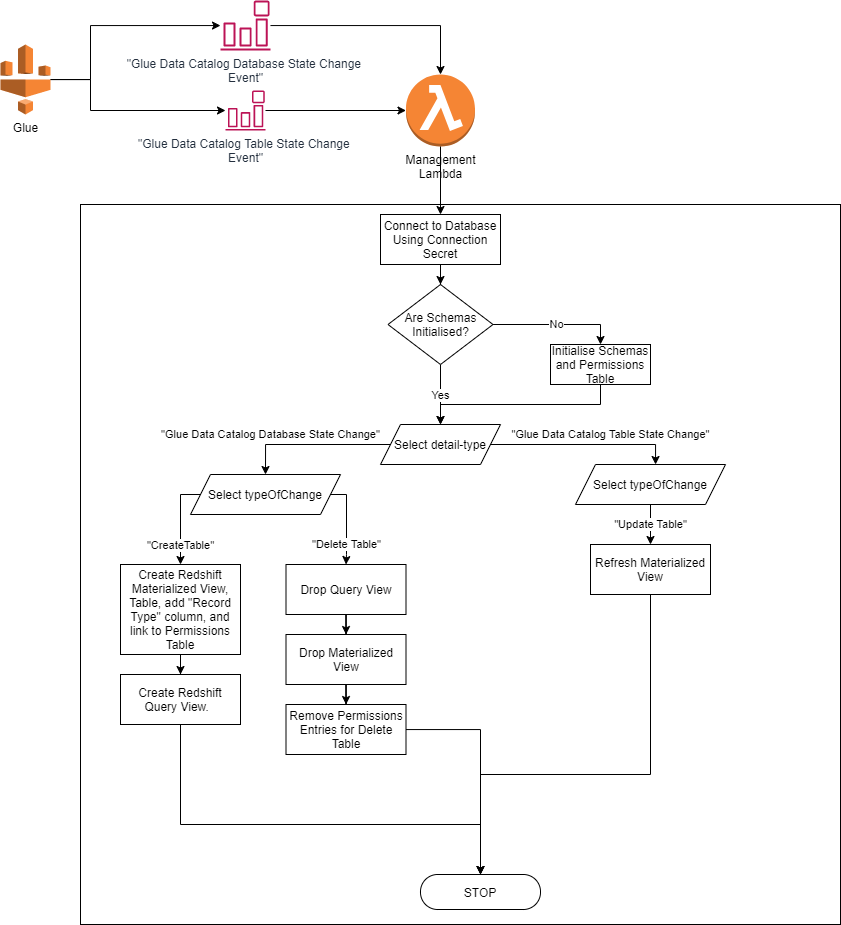
Within the 2 aforementioned events, there are 3 different “typeOfChange” values that need to be handled separately by the Lambda:
- “CreateTable” – this is triggered when a new table is created. It requires a Materialized View to be created on top of the Spectrum Schema Table, the addition of a “Record Type” column that can be used to control permissions (note: You can choose to use different RecordTypes based on different Row Type for Row-Based security or you can use the same value (e.g. the Glue Catalog Table Name) as the value for the “RecordType” column), and finally the creation of the Redshift “Query view” on top of the Materialized View (e.g. the view that the user will access);
- “DeleteTable” – this is triggered when an existing table is deleted. You may choose not to do anything when this happens, and keep the existing materialized view in place (for example, to ensure Dashboards continue to work correctly), or you can choose to drop the views from the database to recover space;
- “UpdateTable” – this is triggered when the table is refreshed (e.g. new data is loaded) and potentially when a new column is added to the table. Because a Redshift Materialized View (in this context) is a point-in-time representation of a spectrum table, it is important to instruct the Materialized View to updated when underlying data or structures change. This involves using the Redshift REFRESH MATERIALIZED VIEW command to update the table.
The following diagram shows how the logic within the Lambda works:
As well as ensuring the Redshift views stay in sync with the Glue Catalog Tables, you may want to add a “User Management Lambda” to additionally:
- Grant users access to a Spectrum Table, by adding an appropriate record to the “Permissions” table;
- Revoke access to a Spectrum Table, by removing the relevant record from the “Permissions” table.
This concludes the overview of implementing Row-Level security using AWS Glue, Lambda, CloudWatch, and Redshift. The outlined solution allows Row-Level security to be implemented against data contained in S3 and ensures that the Redshift database is kept synchronised with the associated Glue Catalog.
These articles discussed an edge-case on the use of Redshift as a data source for a reporting tool that did not support integration with AWS S3 nor the use of an existing user’s IAM credentials. However, this approach remains useful for those who are using such a reporting system.
Note: This article is an opinion and does not constitute advice – any actions taken by a reader based on this article are at the discretion of the reader, who is solely responsible for the outcome of those actions.


