Part of the challenge of using some reporting applications on AWS is the limited connectors that are often available.
A recent challenge required reporting on data that was held in S3 and also to apply row-level security to that data. The reporting application in question did not have connectors for S3 but could connect to a database.
This article describes how I achieved this aim using AWS services. This article is in two parts – Part I (this part) describes the configuration of the components at a high level. The next article will discuss how the objective can be automated.
Challenge
The obvious approach was to make use of AWS Spectrum External Schema against a Glue Catalog.
However, The first challenge in implementing row-level security is the way that the external schema is treated in Redshift from a permissions perspective. There is no way to restrict access to certain objects in the external schema. A user either has access to the schema or not. It was an “all or nothing” scenario.
The second challenge is that even if you create a view on top of the External Schema, the user would not be able to see any data unless they had access to the External Schema. Therefore, we are back to where we began – an “all or nothing scenario”.
Solution
The solution was to create a layer between the External Schema and the User that was not a basic view. This layer was not to be a standard view, but a materialized view. A materialized view – for all intents and purposes – is a table. When the view is created, all of the data is read from the source (in this case, S3) and persisted in the Redshift Database. This has both benefits and drawbacks:
Benefits
- Query performance is improved – your data is stored directly in Redshift, there is no call to S3 when a query is performed;
- Data types can be sensible – The Glue Data Catalog is very liberal when it comes to determining column data types. When using a materialized view, you can create the view with much tighter data types than the types that Glue would determine itself – without the need for manually updating the Glue Catalog
Drawbacks
- Because data is physically stored in Redshift, you pay for the volume of data this is stored;
- The Materialized views need to be refreshed when the data is updated in S3 (how to do this automatically will be discussed in Part II).
Basic Infrastructure Diagram
The solution involved the following high-level components:
- An S3 Bucket to contain the files (of course);
- A Glue Catalog that points to the S3 Bucket;
- An External Schema in Redshift (i.e. Spectrum) that points to the Glue Catalog;
- A Materialized View that included an additional “record type” metadata column;
- A User View that would provide access to the Materialized view, and filter the data that the user could see based on the record type.
The following architecture shows how these components are connected:
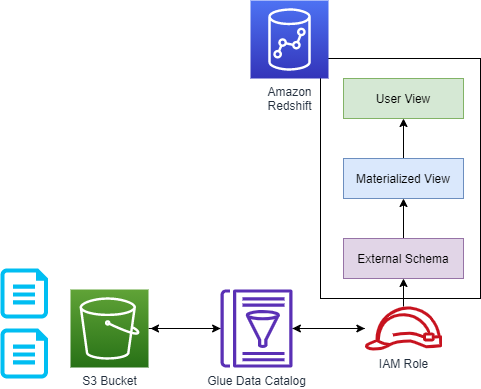
Amazon Redshift Data Model
The Redshift data model contains 4x different schemas:
- An External Schema that is connected to the Glue Catalog. The user does not have access to this schema;
- A middleware schema that contains materialized views. When the materialized view is created, a derived “Record Type” column is added to the view to indicate the security marking for that row (or, indeed, all rows) – and this is used to implement row-level security. The user also does not have access to objects in this schema;
- A permissions schema that contains a Permissions table with a list of User Names and “Record Types” the user has access to. The user does not have access to the objects in this schema either;
- Finally – a Query Schema, containing query Views. This view returns all records from the materialized view where the Record Type exists in the Permissions Table for the user running the query (the user name can be retrieved in this view using the Redshift CURRENT_USER function). The user requires read access to all objects in this schema.
The following diagram shows how these objects are linked:
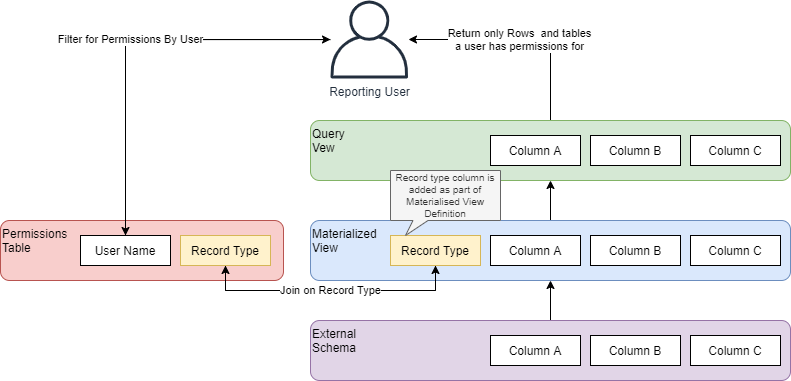
Conclusion
And that’s it!
With the above approach:
- A user can run all Query Views – a requirement, for example, to avoid errors when you have Dashboard Applications that are connecting to Redshift;
- When a user retrieves a view, the view is filtered to return only the records they have access to. If a user has access to none of the records, the view will still return – but will contain no data;
- There is no way for the user to access data other than through the query View;
- The same approach works with multiple Glue Catalog Tables and therefore also supports table-level security for users.
Note: This article is an opinion and does not constitute advice – any actions taken by a reader based on this article are at the discretion of the reader, who is solely responsible for the outcome of those actions.


